
Demo Videos
Automating Oracle Cloud testing with Tricentis Tosca
In this webinar, we show you how Tricentis Tosca provides fast,...

Data analysis often requires restructuring and summarizing data to detect patterns and insights effectively. This post explores the concept of pivoting in Oracle SQL, from creating simple PIVOT queries to advanced techniques like dynamic pivoting and handling multiple columns. Additionally, you will learn how to optimize pivot operations, address common challenges, and apply these methods in practical scenarios like sales analysis and performance reporting.
Pivoting refers to the process of transforming rows into columns to present it in a more readable tabular format. In Oracle SQL, we typically use the PIVOT clause for pivoting to aggregate and reorganize data, making it easier to summarize, analyze and interpret. data.
For example, in the illustration below, a sales table has been transformed using the PIVOT clause. You can see that in the original table, the Region column has two distinct values, East and West, and each value becomes a row in the new table. In addition, original table has a Product column with two distinct values, Laptop and Tablet. Those values each become separate columns in the new table. TheSQL PIVOT operation reorganized the data to make a more readable table.
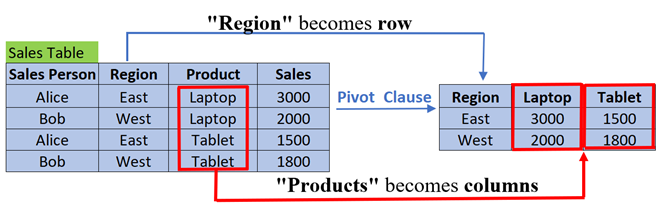
Pivoting facilitates analysis of large datasets by summarizing and grouping them into a more concise format. The transformation lets you compare values across different categories or even time periods.
For example, in the illustration above, a pivot query can rearrange the columns Sales Person, Region, Product and Sales, so that each product becomes a column, making it easier to analyze the yearly sales performance for each product.
Pivoting allows you to compare data across different categories. When rows from a table are transposed into columns, it highlights trends and patterns that may not be immediately obvious. Therefore, pivoting shows your data in a more informative layout so you can easily compare values and identify differences.
Below is the syntax for the Oracle SQL PIVOT function:
SELECT *
FROM (
SELECT column1, column2, column3
FROM table_name
)
PIVOT (
aggregate_function(column3)
FOR column2 IN (value1, value2, ..., valueN)
) Alias;This section shows how to use the PIVOT clause in Oracle SQL.
Firstly, lets head over to our oracle SQL developer IDE to create a simple table for this section of the post
We’ll create the simple sales table shown below:
In your Oracle SQL developer IDE, write the following to create and populate the Sales Table:
CREATE TABLE Sales (
"Sales Person" VARCHAR2(50),
Region VARCHAR2(50),
Product VARCHAR2(50),
Sales NUMBER
);
INSERT INTO Sales ("Sales Person", Region, Product, Sales) VALUES ('Alice', 'East', 'Laptop', 3000);
INSERT INTO Sales ("Sales Person", Region, Product, Sales) VALUES ('Bob', 'West', 'Laptop', 2000);
INSERT INTO Sales ("Sales Person", Region, Product, Sales) VALUES ('Alice', 'East', 'Tablet', 1500);
INSERT INTO Sales ("Sales Person", Region, Product, Sales) VALUES ('Bob', 'West', 'Tablet', 1800);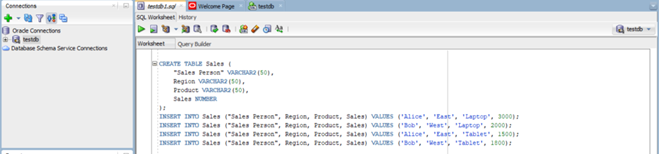
Highlight and run the entire query
Now, let’s run a query to return the table we just created.
SELECT * FROM sales;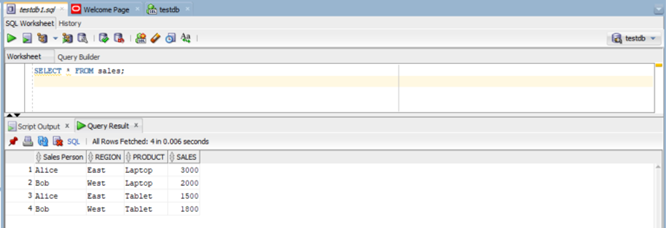
Great! Our table is ready.
To pivot a data table using static values, you explicitly use the PIVOT clause to specify the values you want to pivot.
In this scenario, we’ll use the static values Laptop and Tablet to create separate columns for the aggregated Sales values.
In other words, we want to group the Sales table by Region instead of by Sales Person, thereby creating a separate column for the aggregated Sales values of Laptop and Tablet.
SELECT *
FROM (
-- Step 1: Select the base data for pivoting
SELECT region, product, sales
FROM Sales
)
PIVOT (
-- Step 2: Aggregate the SALES column using the SUM function
SUM(SALES)
-- Step 3: Pivot the PRODUCT column with specific static values
FOR product IN (
'Laptop' AS laptop, -- Creates a column named "laptop" for "Laptop" data: static value1
'Tablet' AS tablet -- Creates a column named "tablet" for "Tablet" data: static value2
)
) PivotTable; -- Step 4: Alias the pivoted result as "PivotTable"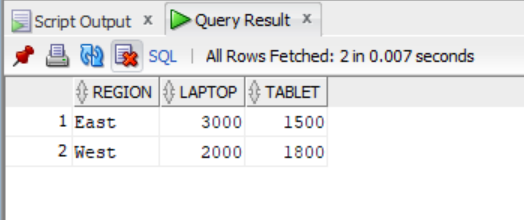
As you can see in the output table, the transformed or reorganized data lets you easily see the aggregated Sales of each product (in columns) for each Region (rows).
Pivoting data with dynamic values is a way to transform rows into columns without specifying the exact values to pivot on. This is useful when you don’t know all the possible values in advance or when values frequently change.
Suppose you want to transform the rows for distinct Regions (East, West) into columns, and aggregate sales data for each product across those regions. This is the query below.
-- Create the GTT so that we can see the output of this query
CREATE GLOBAL TEMPORARY TABLE TempPivotOutput (
Product VARCHAR2(50),
East NUMBER,
West NUMBER
) ON COMMIT PRESERVE ROWS;
-- Dynamic query block
DECLARE
dynamic_query VARCHAR2(4000);
column_list VARCHAR2(4000);
BEGIN
-- Generate the dynamic column list for the pivot
SELECT LISTAGG('''' || region || ''' AS ' || LOWER(region), ', ') WITHIN GROUP (ORDER BY region)
INTO column_list
FROM (
SELECT DISTINCT region
FROM Sales
);
-- Construct the dynamic pivot query
dynamic_query := '
INSERT INTO TempPivotOutput
SELECT *
FROM (
SELECT product, region, sales
FROM Sales
)
PIVOT (
SUM(sales)
FOR region IN (' || column_list || ')
)';
-- Execute the dynamic query
EXECUTE IMMEDIATE dynamic_query;
END;
/
-- Query the GTT
SELECT * FROM TempPivotOutput;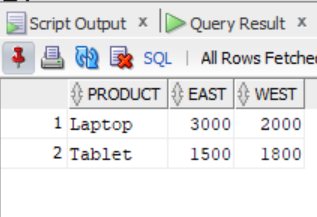
The output shows that the query generated columns dynamically based on the unique values in the Region column of the sales table. The dynamic part lets the query handle any number of regions without rewriting the query.
Also note that storing the output in a temporary table lets you handle dynamic data transformations effectively because the table stores results for further processing or reporting.
We can also pivot multiple columns simultaneously in Oracle SQL. Suppose you want to pivot both Region and Sales Person while aggregating the sales data. Here’s how to achieve this:
SELECT *
FROM (
-- Select the columns to pivot
SELECT product, region, "sales person", sales
FROM Sales
)
-- Perform the pivot operation
PIVOT (
-- Aggregate function to apply to the values (SUM of sales)
SUM(sales)
-- Specify the columns to pivot (region and sales person)
FOR (region, "sales person") IN (
-- Define the pivot values and their corresponding column aliases
('East', 'Alice') AS east_alice, -- Pivot value for East region and Alice sales person
('East', 'Bob') AS east_bob, -- Pivot value for East region and Bob sales person
('West', 'Alice') AS west_alice, -- Pivot value for West region and Alice sales person
('West', 'Bob') AS west_bob -- Pivot value for West region and Bob sales person
)
) PivotTable;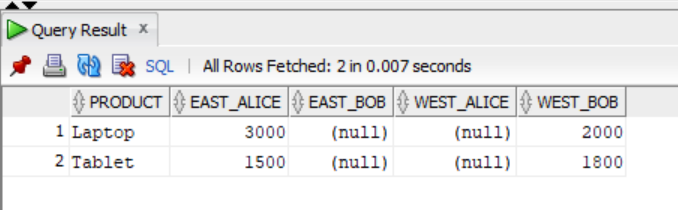
Note that the PIVOT clause in this case requires specifying the exact values to pivot, which can be limiting if you have many unique values. But this is not the case with the dynamic PIVOT query because it generates the pivot values dynamically.
Next, we’ll look at an advanced technique involving the use of Oracle SQL PIVOT: combining it with other SQL functions. Then we’ll talk about performance when using PIVOT clauses.
Oracle SQL allows combining the PIVOT operation with other functions, such as analytical functions, window functions, and subqueries. For example, let’s say you want to calculate the total sales for each product in each region, and also calculate the average sales for each product across all regions. Below is a query to achieve this:
SELECT *
FROM (
SELECT product, region, sales
FROM Sales
)
PIVOT (
SUM(sales) AS total_sales,
AVG(sales) AS avg_sales
FOR region IN ('East' AS east, 'West' AS west)
)
ORDER BY product;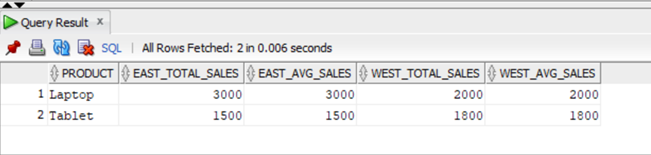
This query pivots the Sales for each Product in each Region, and also calculates the average sales for each product across the Region.
When working with Oracle SQL PIVOT, you must consider how fast your queries will run. When you pivot a table, Oracle does a lot of work behind the scenes to transform the data, which can slow your queries.
One way to make them faster is to use indexes on the columns you want to pivot. An index is like a map that helps Oracle find the data it needs quickly. Here’s an example that creates an index on the Region column:
CREATE INDEX idx_region ON Sales (region);Another way to make your query faster is to limit the data range by filtering rows with a WHERE clause before applying the pivot operation.
Next, here’s how to troubleshoot common issues like null values, debugging, and optimization.
Remember that when we discussed pivoting multiple columns, our output table, shown below, had some null values.

To deal with these null values, you can use built-in functions like NVL, NVL2, or COALESCE, which replace null values with a value you specify. The NVL function takes two parameters. If the first parameter is NULL, it replaces it with the second parameter.
The NVL2 function takes three parameters. It compares the first parameter and returns one of the other two parameters depending on whether the first parameter is NULL or not. Meaning that if the first parameter you provided is NOT NULL, it returns the second parameter, but if the first parameter is NULL, then it returns the third parameter.
You can use the COALESCE function to return the first non-NULL value from a list of expressions. Unlike NVL, which handles just two parameters, COALESCE can handle multiple expressions.
Now, let’s modify the query, and this time replace the null values with zeros using the NVL function.
SELECT
product,
-- Replace NULL values in the pivoted columns with 0 using NVL
NVL(east_alice, 0) AS east_alice, -- Sales for Alice in East region; NULL replaced with 0
NVL(east_bob, 0) AS east_bob, -- Sales for Bob in East region; NULL replaced with 0
NVL(west_alice, 0) AS west_alice, -- Sales for Alice in West region; NULL replaced with 0
NVL(west_bob, 0) AS west_bob -- Sales for Bob in West region; NULL replaced with 0
FROM (
-- Base data selection
SELECT product, region, "Sales Person", sales
FROM Sales
)
PIVOT (
-- Aggregate the sales values using SUM
SUM(sales)
-- Dynamically pivot the "Sales Person" and "Region" combinations
FOR ("Sales Person", region) IN (
-- Define pivot values with aliases for each combination
('Alice', 'East') AS east_alice, -- Column for Alice in East region
('Bob', 'East') AS east_bob, -- Column for Bob in East region
('Alice', 'West') AS west_alice, -- Column for Alice in West region
('Bob', 'West') AS west_bob -- Column for Bob in West region
)
) PivotTable; -- Alias for the pivoted table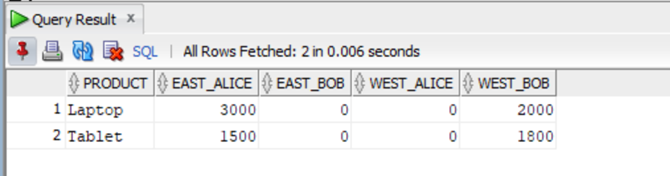
Bravo! The NVL function replaced the null values with 0.
If a pivot query doesn’t produce the expected results:
Pivoting in Oracle SQL has many real-world applications.
Imagine a sales table where you’ve recorded various clients, repeatedly listed down the rows, along with the products they purchased, their key account managers, and the value of each sale. This table doesn’t explicitly provide important information, like which products had the highest sales. Using a pivot operation, you can easily pivot the data to have columns for the different clients, with products in rows, aggregating sales values for each client-product combination in a summary table.
A retail business uses the Oracle SQL PIVOT function to analyze sales performance across different regions, products, and time periods to identify top-performing products and regions. Student grade analysis A university uses the Oracle SQL PIVOT function to analyze student grades across different courses, semesters, and departments to identify trends and patterns in student performance.
Pivoting in Oracle SQL is a powerful technique that transforms and summarizes data, making it easier to analyze and understand. By using the PIVOT clause, you can transpose rows into columns, aggregate data, and create customized reports. This feature is particularly useful for data analysis, reporting, and business intelligence applications, allowing users to gain valuable insights from their data.
This post was written by Theophilus Onyejiaku. Theophilus has over 5 years of experience as data scientist and a machine learning engineer. He has garnered expertise in the field of Data Science, Machine Learning, Computer Vision, Deep learning, Object Detection, Model Development and Deployment. He has written well over 660+ articles in the aforementioned fields, python programming, data analytics and so much more.