
The future of testing is agentic: What does this mean for you?
Hear our panel of experts share their perspectives on this and other...
This blog brings to light some of the why behind why we chose Anthropic’s Computer Using Agent, and what makes our agentic AI so powerful.

In the prior blog, we previewed some of the reasons that we settled on using Anthropic’s Computer Using Agent (CUA) over other alternatives and promised to provide more information as to what and why, with facts and figures. If you haven’t read that blog, check it out here.
In this blog, I hope we can bring to light some of the “why” behind our decisions, and what makes our agentic AI so powerful.
To start with, let’s outline the basics. How does computer use actually work with an AI? Can’t generative AIs just generate text? Well, if we ignore diffusion models, TTS, and other modalities, then that’s sort of true, but it turns out you can do a lot with text.
Let’s start with tools. Tools are not new to generative AI, the first tool using models came out in May 2023, with OpenAI following swiftly in June of the same year. But what is tool use? There is a great guide here if you want details, but for the sake of brevity I will summarize.
Tool use is giving the AI an alternative way to respond. Instead of coming back with an answer, it can ask a question, but only from a list of available methods you give it. These “methods” (functions/tools) are APIs for AI. It is a way to provide the AI with the capability to reach out and get real time, up-to-date factual information that it can use to resolve the query. Here is a good example from OpenAI:
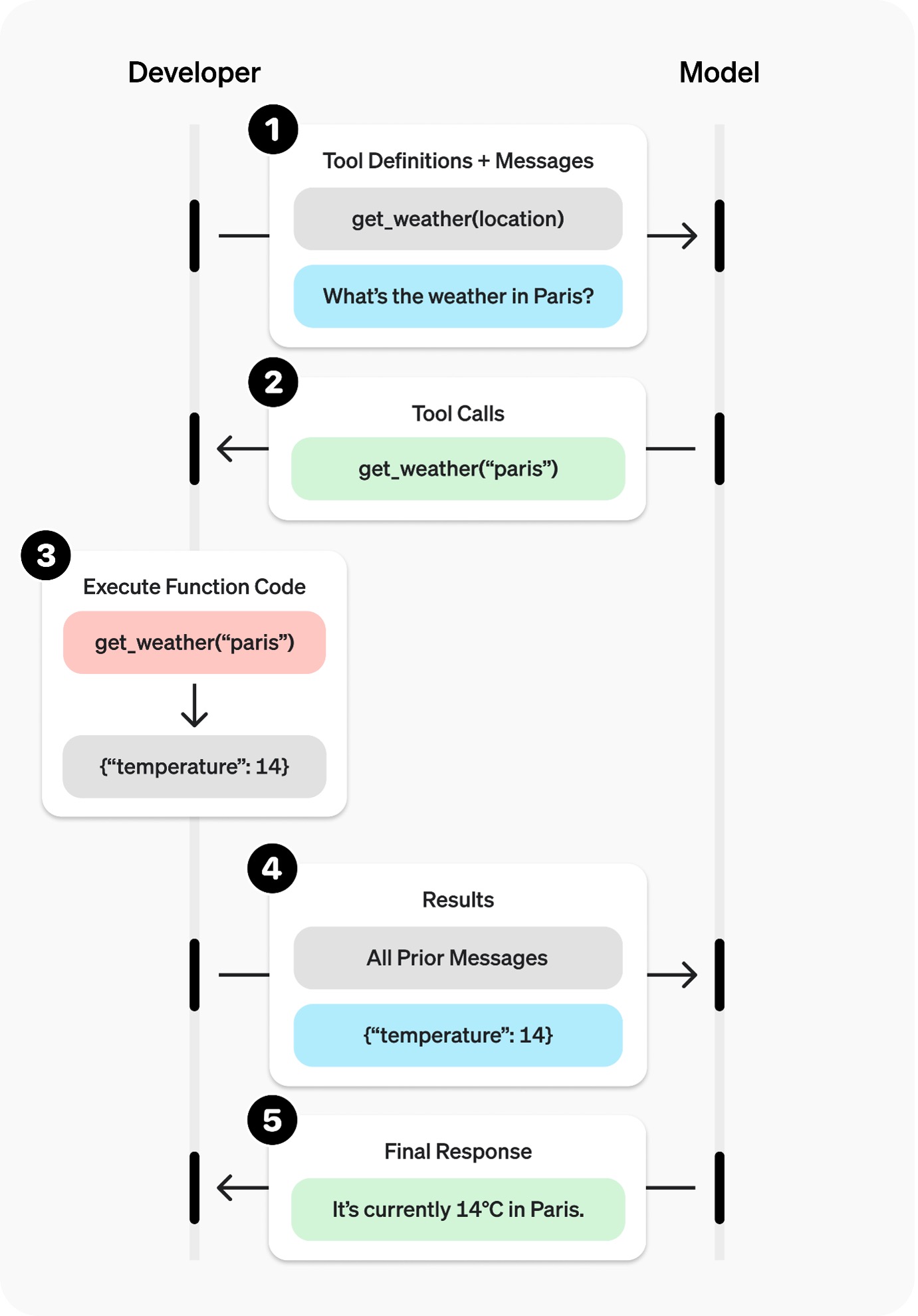
Figure 1: https://platform.openai.com/docs/guides/function-calling
In our application, the “reaching out” is giving the AI the ability to get the status of the app, see what’s on the screen, or take action based on what it sees. Reaching out to the human for help is also a tool, it’s just that you are on the other end of that API call as a biological servant to the new AI overlord. We’ll call that “Human in the loop” just to keep the populace calm.
Having established the basics of tool use, let’s jump into the second capability we need, multimodality. When we say a model is multimodal (try saying that 10 times fast …), we often mean it accepts multiple forms of input (modes) but outputs a single mode (text). Many models’ multimodality means models modes morph moderated by mission (ok I’m done now …). Translated into English: You can have different input modes (prompts), and different output modes (responses). Here is a great diagram showing this:
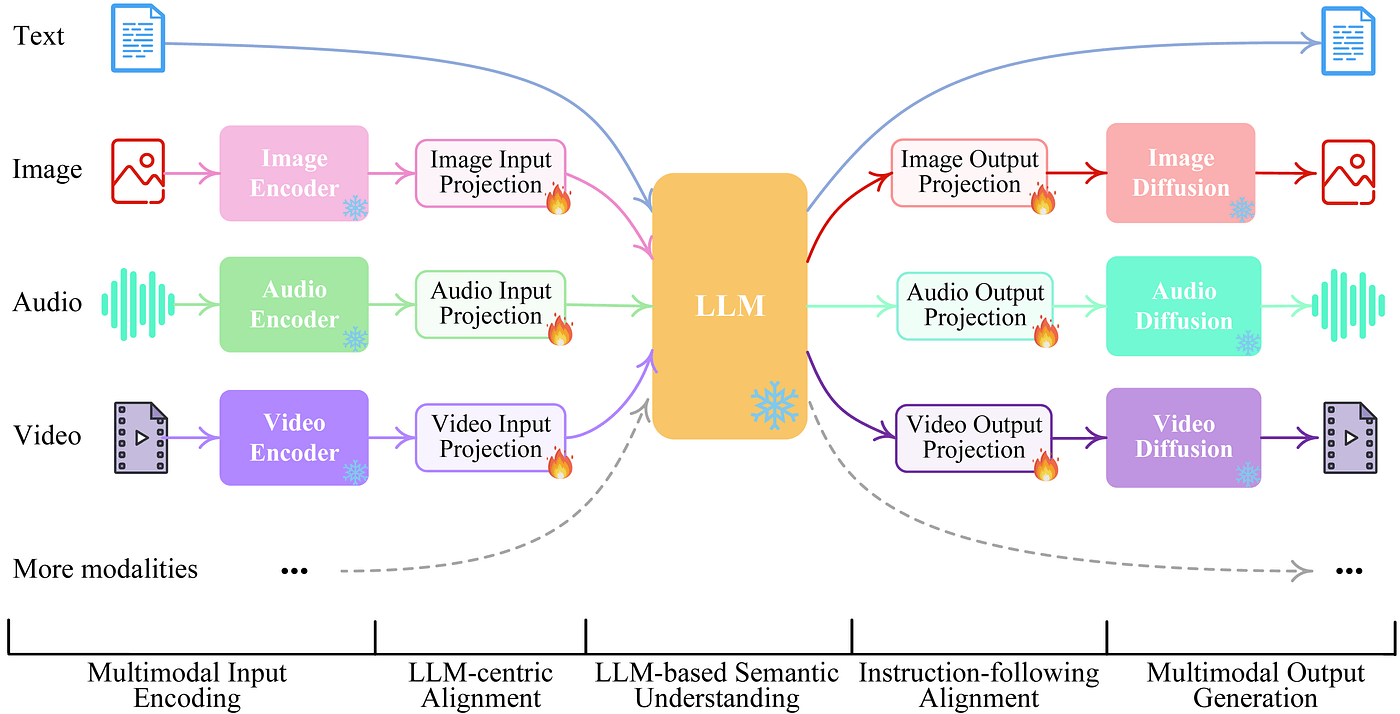
The modes we care about most here are Vision and Text.
Why is Vision so important?
LLMs speak text, so why can’t we just feed them the HTML of an application, and have them determine the best action to take? The LLM knows how to code, right? It’s true that if you give a HTML snippet to ChatGPT and ask what’s going on, it will do a great job of telling you. But take it a level deeper, and we find out that AI is very much like us – there is such a thing as too much cognitive load. In the AI world, these are called “Long horizon tasks,” where there are multiple conceptual steps to perform to get to the answer.
Let’s outline this long horizon for the task of taking in a HTML page, and spitting out actions:
Most of the cognitive load in this scenario is asking the AI to act like a browser rendering engine, figuring out the relation of elements to each other, visibility, etc. Sometimes, depending on how large the context is, this task may be impossible. Here is the key fact though – we don’t work that way as humans. If you wanted to find an element to act on in Chrome, most of us would just visually locate it – and not spend too much time or energy thinking about our actions. By using vision models, we can do much the same thing with AI, finding something without the added cognitive load. In the prior blog, we went into detail about how AI can see, so I won’t repeat that here! But one key point to reiterate here is that multimodal AIs are trained to understand what’s present in an image, making the cognitive load chain much shorter than other AIs.
This leads us to the final point: how AI models are trained is crucial to their success for a particular use case. Language models are few-shot learners,. That proved prescient in most cases, but only when the basic competency was already there.
Take this example: we gave the same prompt to GPT4o and Claude 3.7 Sonnet.
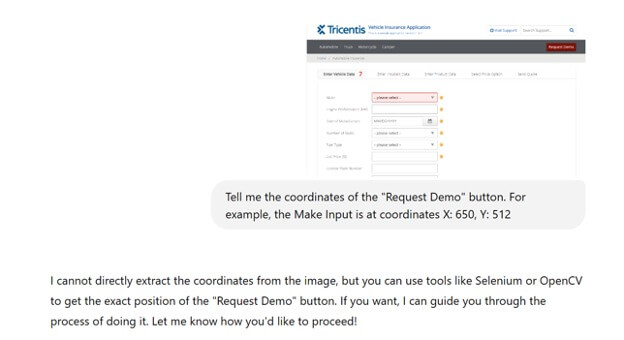
Figure 2 GPT4o
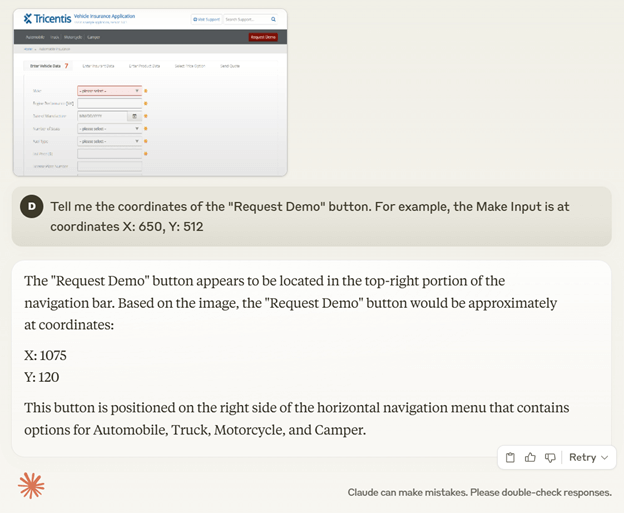
Figure 3 Claude
The Claude model has been trained on how to precisely locate actions within an image, whereas the GPT model has not. No amount of prompting or examples will be able to overcome that deficiency, as it’s an inherent, trained trait of the Claude model.
Until very recently, the OpenAI Operator model had no API, which was a barrier for us to rolling up our metaphorical sleeves and figuring out what value it provides. Closed models don’t allow you to plug in your own capabilities, rendering them mostly useless as enterprise tools. No one wants to have their tests run on OpenAI’s machine in their cloud.
OmniParser is a system for identifying interactive controls or regions on a computer interface. It uses a combination of Optical Character Recognition (OCR) and Control Detection neural networks to pick controls that would be useful for a computer use agent. This improves on techniques used by competing solutions, as only the most appropriate controls are output, removing unnecessary controls and regions that can confuse the LLM predictions for next action.
The networks employed are YOLOv8 for control/icon detection and EasyOCR or PaddleOCR for text recognition. The outputs are combined to generate control regions with text content. Any controls without text content (e.g., icons, images, empty controls) are sent to the Florence2 classification network to predict the type of control – this prediction is used as the “content” for those controls.
OmniParser is the backend to OmniTool. OmniTool takes the predictions from OmniParser, and feeds these to a LLM to determine the action to take on the current screen. Multiple LLMs are supported, including OpenAI (4o/o1/o3-mini), DeepSeek (R1), Qwen (2.5VL), and Anthropic (Claude 3.5v2).
OmniTool works similarly to existing agentic navigation agents, but performance is improved by annotating the screenshot with the more ideal set of controls from OmniParser. Competing solutions, such as web agents, typically parse the DOM for control regions, and this results in excess and sometimes hidden controls being presented to the LLM.
The information sent to the LLM in the prompt includes the raw screenshot, an annotated screenshot, and a list of controls matching the annotations.
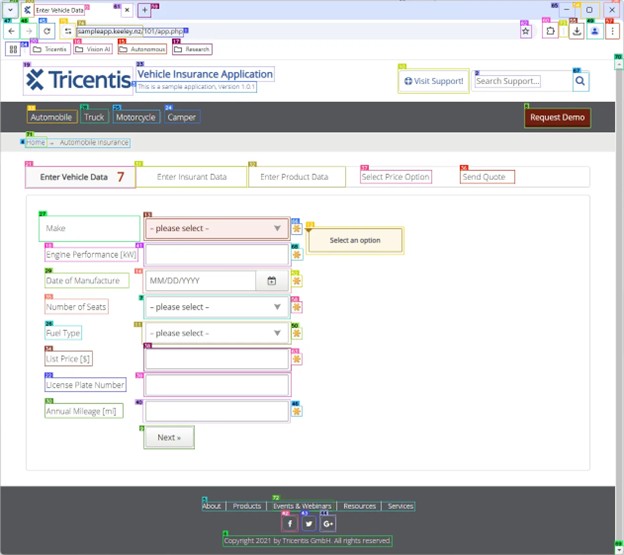
The OmniParser annotation data sent to the LLM only includes the ID, Control Type (text/icon), and Content:
ID 0: Text: Enter Vehicle DataID 1: Text: sampleapp.keeley.nz/101/app.phpID 2: Text: Search Support....ID 3: Text: This is a sample application, Version 1.0.1eID 4: Text: Home + Automobile Insurance.ID 5: Text: About ProductsEvents & WebinarsResources ServicesID 6: Text: Copyright 2021 by Tricentis GmbH. All rights reserved.ID 7: Icon: please select -ID 8: Icon: Request DemoID 9: Icon: Next >ID 10: Icon: @ Visit Support!ID 11: Icon: please select -ID 12: Icon: Select an optionID 13: Icon: please select -...The only control types are “Text” and “Icon.” Icon represents anything that is not text.
When using Claude 3.5v2, Claude’s native computer-use tool is called to generate actions, which are based on coordinates. In this case, the annotated screenshot is not presented, only the raw screenshot and OmniParser data is sent. We found that as Claude 3.5v2 is excellent at navigation and screen interpretation already, the extra OmniParser data only offers a minor improvement in steering.
For all other LLMs, a longer prompt is used, specifying actions to take on one of the control IDs present in the OmniParser output. This greatly improves performance for agentic control based on these models.
We took a selection of 100 human-labeled screenshots and compared the accuracy of OmniParser output to our own Vision AI detection system.
Overall comparison
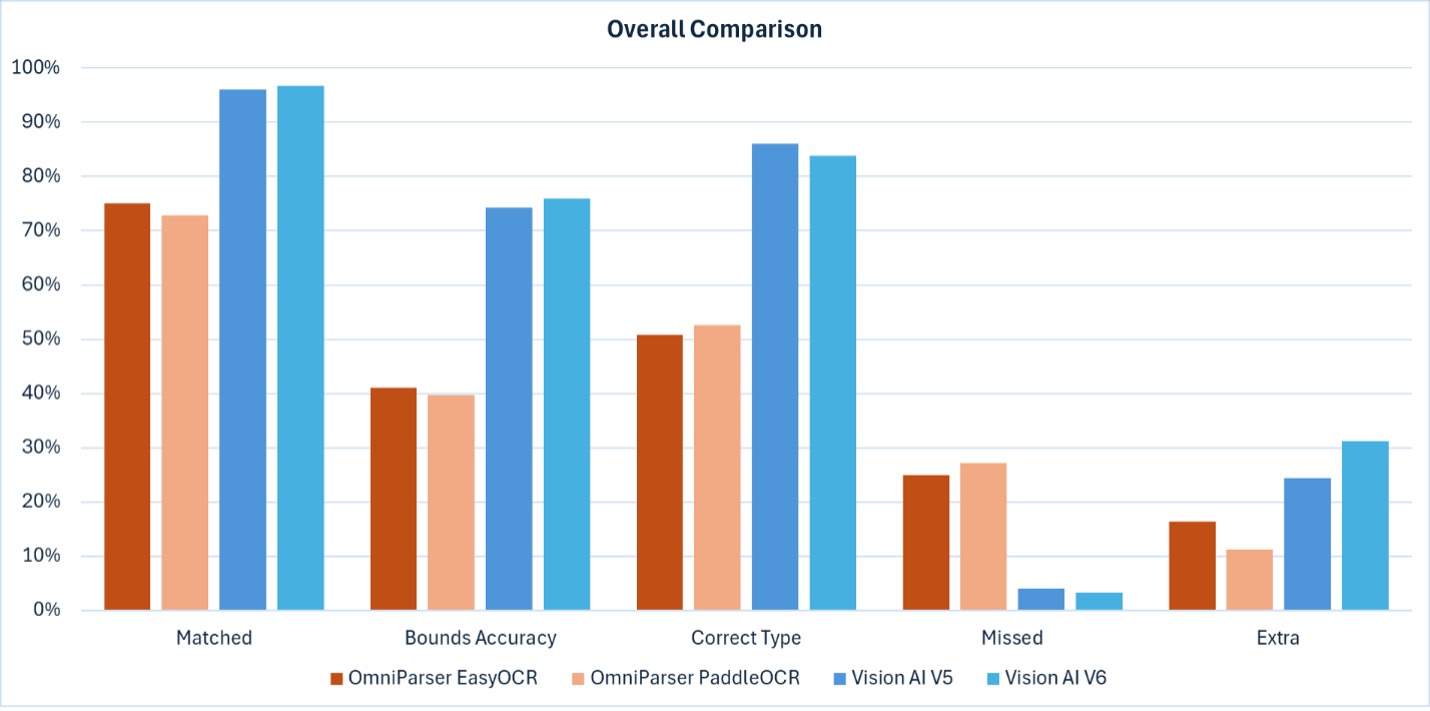
Here we compare key metrics for OmniParser (orange) versus Vision AI (blue). The two OmniParser variants are EasyOCR and PaddleOCR for text detection. The two Vision AI variants are using our latest Version 5 and Version 6 control detection networks. OCR for Vision AI is based on Azure’s Read API v3.2 for both variants.
Overall, Vision AI is far superior to OmniParser in detection accuracy.
Typically, OmniParser predictions are larger and/or less detailed than Vision AI predictions. For the use case of LLM Navigation agents, this has the benefit of reduced prompt size (fewer controls), which improves control selection. However, it can lead to loss of fine control over individual parts of an interface.
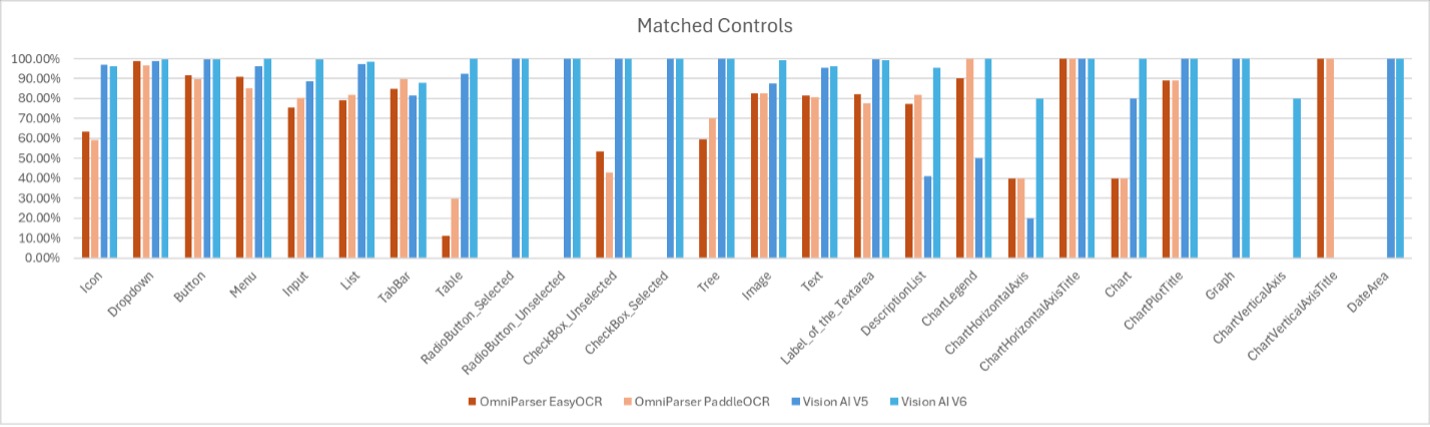
Matches by control type
This chart shows how well the different control types are detected by each network.
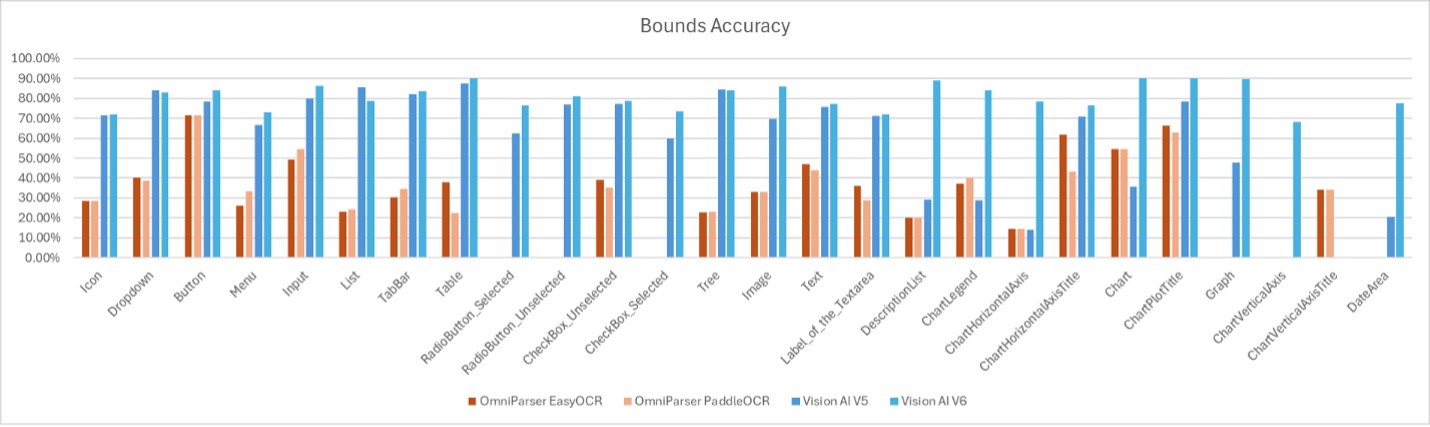
Bounds accuracy by control type
This chart shows the accuracy of the detected bounds for each control type.
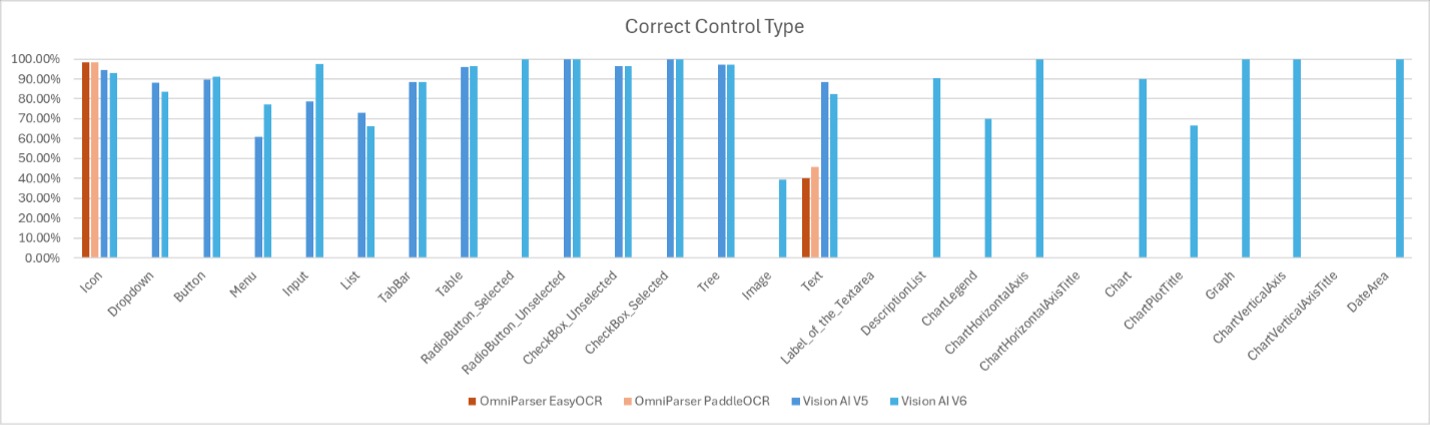
Control type accuracy
This chart shows the accuracy of the detected control type.
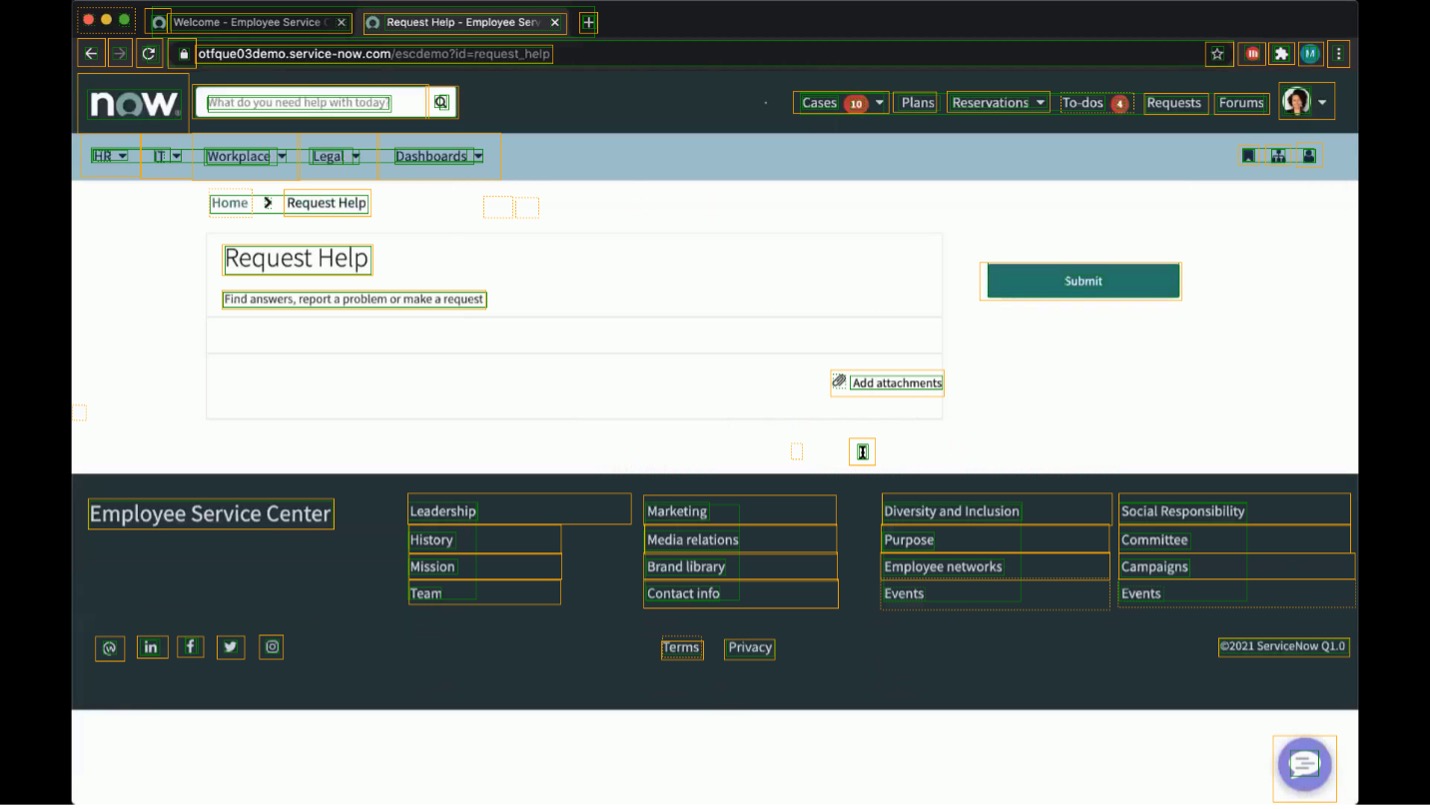
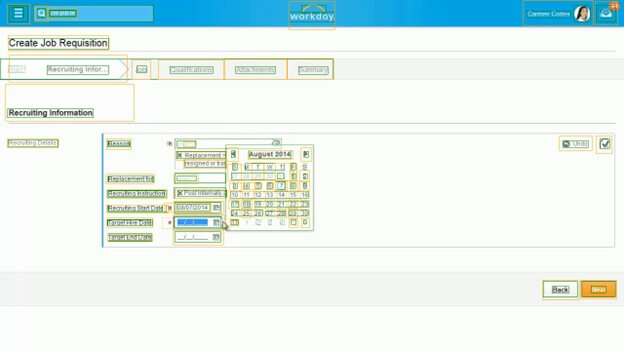
Example of failure modes for OmniParser
Green boxes show expected controls and yellow boxes show OmniParser predictions.
AI-powered computer-using models are designed to interact with digital interfaces autonomously, simulating human-like actions such as clicking, typing, scrolling, and navigating software applications. These models combine vision processing, structured data extraction, and reasoning to understand and execute tasks on computers or web browsers.
Claude’s Computer Use is a multimodal capability that enables it to see, understand, and interact with computer interfaces, in a human-like manner. This capability allows Claude to move the cursor, click buttons, and type text, effectively emulating user interactions with software applications.
This combination of visual interpretation, action planning, and precise interaction enables Claude to perform tasks across various software applications.
Claude’s Computer Use, OpenAI Operator, and OmniParser allow AI to interact with user interfaces, but their approaches differ significantly. Here’s a breakdown of the differences:
Claude’s Computer Use works in a top-down manner:
OpenAI’s Operator follows a bottom-up approach when interacting with web interfaces and operates within a custom version of Chrome:
OmniParser works in a bottom-up approach:
| Feature | Claude Computer Use | OpenAI Operator | OmniParser |
| Scope | Works across desktop applications and web interfaces | Works exclusively in Chrome for web automation | Works in structured applications where UI elements can be extracted and analyzed |
| Processing order | Decides action first → Finds UI element → Retrieves coordinates | Extracts UI elements first → LLM selects action → Executes | Extracts UI elements first → Filters unnecessary ones → LLM selects action → Executes |
| Environment | Works on any software or web UI | Operates in a custom version of Chrome | Can function in various environments but primarily targets structured UI applications |
| UI element handling | Uses vision-based detection to find elements dynamically | Uses structured webpage data to extract and interact with UI components | Uses OCR + object detection (YOLOv8, PaddleOCR) to detect and filter UI elements |
| LLM dependency | Operates autonomously, without requiring an external LLM | Operates autonomously, without requiring an external LLM | Requires an LLM to determine the action after detecting and filtering UI elements |
| Coordinate system | Returns pixel coordinates for UI interaction | Uses structured webpage data for precise element positioning | Uses OCR-based bounding boxes for positioning detected UI elements |
| Execution method | Simulates human-like mouse and keyboard actions based on element coordinates | Makes API calls with partner websites and performs interactions with web elements directly within Chrome | Passes filtered UI elements to an LLM for reasoning and execution |
| Open/closed source | Closed source | Closed source | Open source |
Integrating Claude Computer Use with Tricentis Vision AI creates a powerful AI-driven test automation and UI interaction system by combining coordinate-based execution with precise control matching. This approach eliminates the need for traditional control identification methods (such as name, ID, or attributes) and instead ensures accurate execution through coordinate-based control matching.
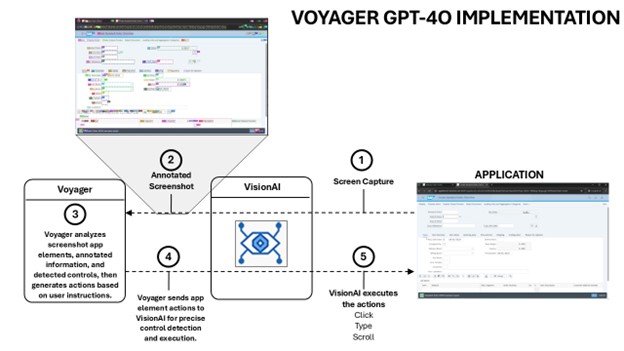
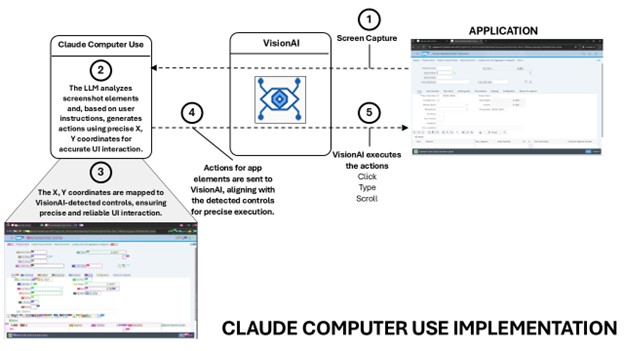
While Claude Computer Use provided a solid foundation for UI automation, it did not work optimally out of the box for complex enterprise workflows.
Handling complex multi-step controls:
By integrating Vision AI, custom tooling, and guardrails, we addressed Claude Computer Use’s limitations in handling complex UI interactions, table steering, and redundant actions. Vision AI provided accurate control detection, while our custom automation guardrails eliminated inefficiencies and improved execution accuracy, making enterprise test automation more reliable and scalable.
Control detection and contextual awareness:
Eliminating redundant actions:
Automatic Tosca script generation for scalable testing:
We tested Voyager v1.2.0 (Current GPT-4o Implementation) and Claude Computer Use to evaluate how well each model handled long-horizon test execution — executing complex, multi-step workflows autonomously for end-to-end Order-to-Cash (O2C) automation while maintaining context, correcting errors, and minimizing human intervention.
This experiment leveraged Claude Computer Use + Tricentis Vision AI, a hybrid AI-driven automation approach, to optimize test execution accuracy and efficiency.
What is Order-to-Cash (O2C)?
Order-to-Cash is a critical business process that covers the entire lifecycle of a customer order — from order creation to payment collection. This includes:
Given its complexity, O2C automation must handle various system interactions, validate data, and adapt to changing UI conditions — making it an ideal test case for evaluating AI-driven test execution.
We found that Claude Computer Use had:
| Metric | Voyager v1.2.0 | Claude Computer Use |
| Test Completed Successfully? | ✅ Yes | ✅ Yes |
| Human Assistance Required? | ❗ 1 time | ✅ 0 times |
| Efficiency Score (Higher = Better) | 🔴 0.45 | 🟢 0.52 |
| Successful Actions (%) | 🔴 87% | 🟢 98% |
| Data Entry Accuracy (%) | 🟢 98% | 🟢 98% |
Learn how to supercharge your quality engineering journey with our advanced testing solutions.
Learn how to supercharge your quality engineering journey with our advanced testing solutions.
