


Our vision for the future of AI-driven testing
How will AI impact the future of testing, and what should you know...
Learn how to supercharge your quality engineering journey with our advanced testing solutions.
Opening disclaimer: I am going to make claims here and provide limited proof. Fear not, fellow truth seekers. Future blog posts will provide numbers, evidence, and elaboration.
We developed our first prototypes of a computer-using agent in April 2023. That’s right, 2023. At the time, we were using GPT-3.5 as a planning AI, with the actual execution being delegated to our internal tooling (Vision AI) to create the instructions and execute them. For evidence, here is a demo video we recorded in May:
It’s a useful demo because this app won’t let you enter a date less than a month in the future, so it effectively date stamps it:

These systems worked really well in demo environments, but they struggled massively in anything more complex. There were a few reasons for this:
We used multimodal models, but even though they could see and explain an image, they were a bit … myopic.
Vision language models break up an image into “patches” which overlap slightly and generate an explanation for each patch.
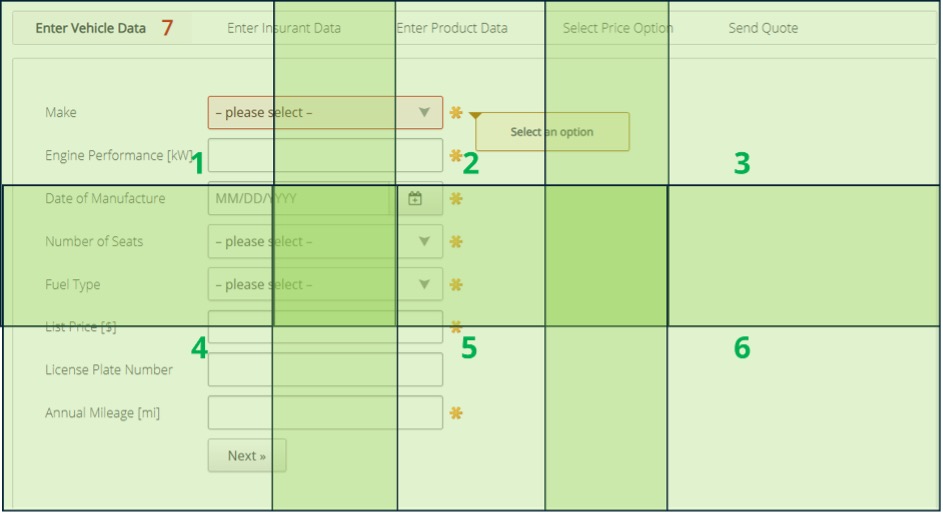
The position of each patch is maintained, and the network “sees” the summaries of each patch and reconstructs an overall view. The problem starts to occur when the interface is complex. Consider the interface below:
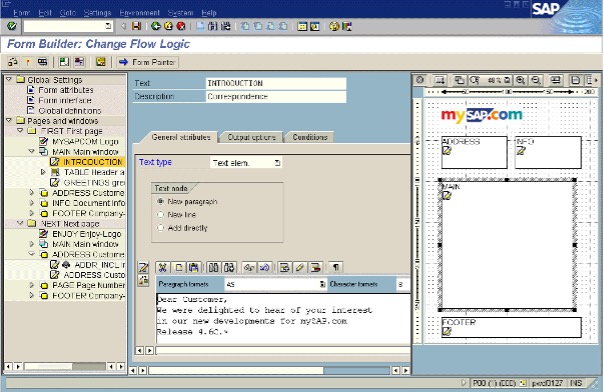
Now imagine that you are asking for it to click the “magnification increase” icon that you can see here:
The blurriness of the model’s vision precluded it from seeing finer details, and even when (by luck) the actual detail you wanted was captured, it had no coordinate system to work with to tell the guiding machine how to locate it.
The models knew about how UIs were used because they had good general knowledge, but they had very little knowledge of what to do when the action was not obvious. Challenging situations included:
As the models had no training in how to do this, it had to be augmented with prompting. This produced better results, but not great results.
This one was infuriating. The model would frequently “see” the UI (for example, a web shop) and have in its own mind what the flow in a web shop should be. The next instruction it offered would often be something like “click the checkout cart button” when no such button was showing on the screen. This was because in the blurry view, the model had determined that this was a product page, and a product page must contain such a button.
At Tricentis, we work with large enterprises, and the early versions of the models were trained on public information. Enterprise applications are very different to mobile apps or Amazon storefronts; they are data dense, require expert knowledge, contain arcane terminology, and have complex user flows.
We frequently ran into problems where the AI would have absolutely no idea what to do and would revert to what it thought a similar flow in an application it had seen before would look like. This led to a prompt-sorcery cycle, wherein the team added more and more prompts, RAG, guardrails, ad infinitum, hoping to reach stability at the expense of generalization.
Rather than asking the AI to see details, we used our Vision AI system to “see” the screen and annotate it for the generative AI. Each box would be colored and numbered so that the system could simply say “Click Box 136” instead of having to provide coordinates! Simple!
Along with improvements in models (GPT-4o), we were able to bring our first agentic solutions to bear in October last year!
This also cured (mostly) the problem of hallucinating controls, because if the control was not there, it could not click on it.
The vision was still a bit blurry. When it came to compact UI elements, the representation of the patch simply did not contain enough information, or it was not accurate enough, often enough to reliably discriminate between compacted elements.
Those other two problems, models not being trained on sequencing or complex data controls, were also not solved. The web of prompt engineering drove us into narrower corners, where the system would work well on simple applications, or on ones where we engineered the prompting, but not in complex, generic enterprise applications.
In October 2024, Anthropic released a computer use feature for its Claude 3.5 Sonnet model. This was the first model we had seen that was trained not just to use a computer, but to do so with localized coordinate systems. Instead of the typical “pick one of these options” approaches used by other open-source browser using AI agents, or trying to parse the HTML, Claude offered the ability to provide specific X and Y coordinates for the actions it recommended:
In addition to this, Claude provided an API that offered the ability to replace the tooling with whatever you wanted.
We will be covering in a later blog just how much difference this made to our use cases, but here are a few of the highlights:
It was not all rosy, however. Some areas where we noticed room for improvement:
The winning combination here was to merge all the technologies together. We used Claude’s innate ability to see better than the other models and translated its coordinate system to the objects that Vision AI detected in the image. Instead of asking it to do primitive actions, we substituted our own Tosca actions.
The result was impressive and immediate. The improved baseline model capabilities, combined with the specific technology capabilities of the Tricentis suite, boosted our first time accuracy on complex SAP transactions from about 60% to about 95%.
But those are just the numbers. Watch as this generative AI-superpowered combination automates applications with zero human guidance on the first try. Not just navigates – completely automates.
In a later blog post, we will cover the differentiators between OpenAI Operator, Claude, and after-model open solutions like Microsoft OmniParser/OmniTool, but the key factor here is the strategic alignment. Anthropic builds products for the enterprise market, much like Tricentis. This mission alignment means that our use cases are constantly being mutually improved.
When we tested the early release of Claude 3.7, we were able to see use-case specific improvements, with the model improving its handling of complex user interfaces, scrolling for off-screen elements, and developing a more nuanced understanding of enterprise iconography and table structures.
Most importantly, it was able to reduce human interaction in the tested flows down to zero. This represented the first time we could truly call the system “agentic.”
Computer-using AI agents have been a long time coming; now they are here, providing amazing opportunities to boost the efficiency of knowledge workers. In the space of QA test automation, it is an incredible opportunity, and we are glad to see competition in the market heating up. With that said, we made the decision back in October to bet on Anthropic as the best-in-class computer-using AI agent for enterprise automation, and our experience so far has shown that to be the winning bet. This recent release of Claude 3.7 has been another step towards models that can really use computers, not just play around in web browsers, and achieve real productivity in real-world situations.
Stay tuned. In an upcoming blog post, we will be sharing our benchmarks, comparisons, and examination of the broader world of computer-using AI!
Learn how to supercharge your quality engineering journey with our advanced testing solutions.
